
What DeepSeek V3.2 Really Tells Us

On December 1, 2025, exactly three years after the launch of ChatGPT, DeepSeek dropped a major surprise at this symbolic moment as the V3.2 model officially went live. The technical report is available.
The release immediately set off a shockwave across the AI community, and many people’s first reaction was that the open source SOTA had just been rewritten again.
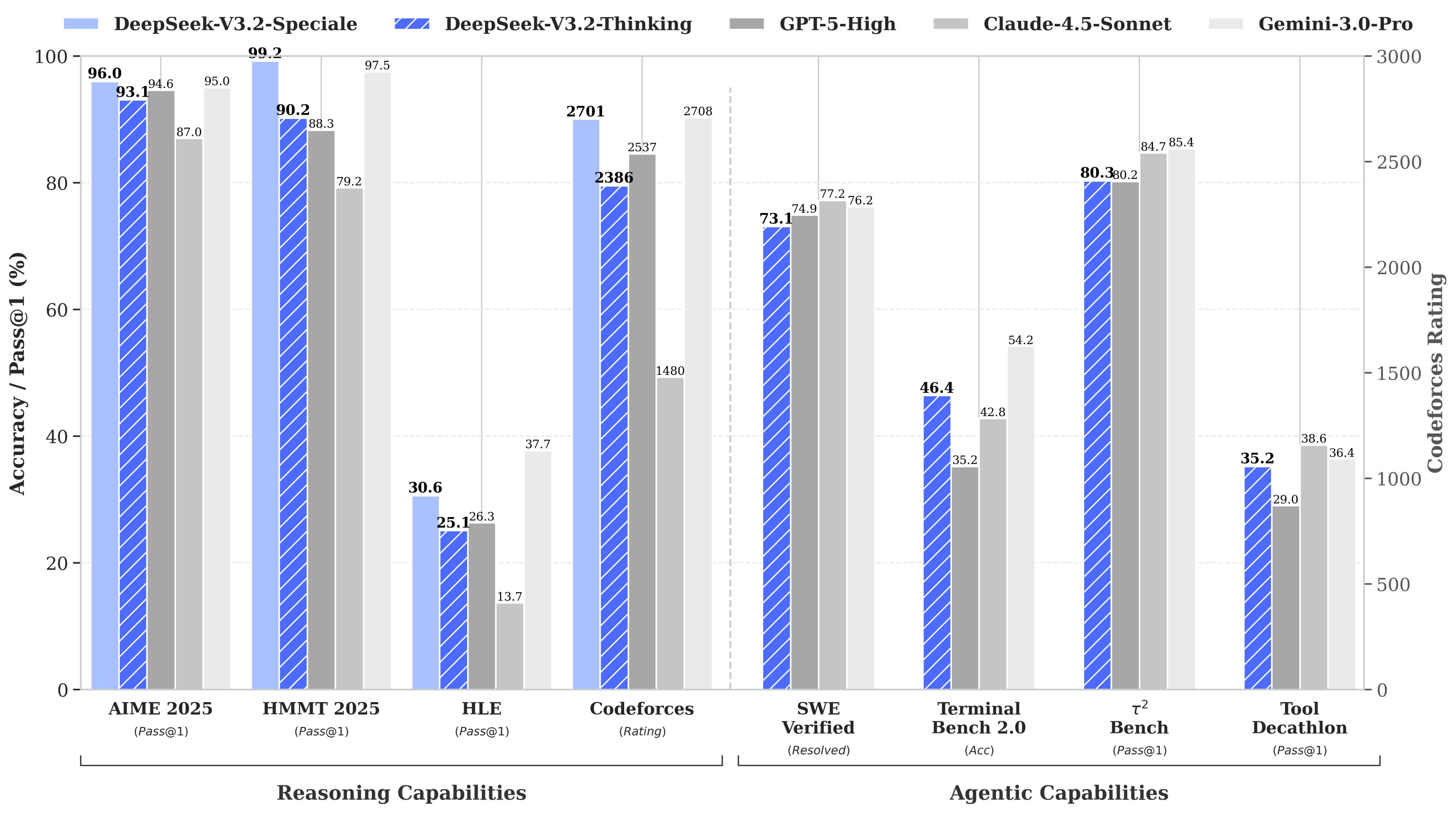
The new model fully lived up to the hype. It not only matches top proprietary systems such as GPT 5, Claude 4.5 Sonnet and Gemini 3.0 Pro across multiple core capabilities, but also delivers impressive results on benchmarks that best reflect real technical strength, including reasoning, mathematics and engineering oriented tasks.
The Speciale version was especially striking, scoring 97.5 percent on math benchmarks like AIME 2025 and HMMT 2025, which made many observers feel for the first time that an open source model can truly go head to head with closed source leaders using actual substance rather than slogans.
What makes V3.2 even more interesting is that it does not pursue any brand new architecture or disruptive innovation. Instead, it pushes DeepSeek’s existing technical line to the limit. It continues to use sparse attention through DSA and maintains a high share of post training, with the key breakthrough coming from scaling up the experimental V3.2 framework and pushing reinforcement learning to an extremely high intensity.

Overseas technical communities described it very plainly as the dsv3.2 exp system pushed to its maximum scale with a massive reinforcement learning phase added on top. Yet it is precisely this strategy of pushing a mature architecture as far as it can go that has made many researchers rethink what is possible.
DeepSeek researcher Gou Zhibin even compared it directly with Gemini 3 by saying that Gemini 3 shows that scaling up pre training continues to work, while DeepSeek V3.2 Speciale shows that scaling reinforcement learning under extremely long context windows can yield equally large gains. This insight matters a great deal because it implies that the ceiling of post training is not fully determined by how good the base model is, and that progress in methods and data can continue to unlock further breakthroughs.
Outside observers have been debating whether compute is already in oversupply and whether the industry has reached a compute collapse. DeepSeek V3.2 gives a very clear answer. There is no collapse and compute remains the central variable that determines who leads the AI race. The team openly disclosed the model’s total training FLOPs and candidly noted that because the pre training compute budget was relatively modest, V3.2 still falls short of proprietary giants like Gemini 3.0 Pro in terms of world knowledge coverage.
Despite these achievements, we acknowledge certain limitations when compared to frontier closed-source models such as Gemini-3.0-Pro. First, due to fewer total training FLOPs, the breadth of world knowledge in DeepSeek-V3.2 still lags behind that of leading proprietary models.

To close that gap, the only path forward is more compute. This view resonates with many long time observers. One of them even commented that knowledge is no longer a differentiator and compute has become the only thing that matters, so it is time to expand the GPU cluster. In a world where most frontier models have similar access to knowledge, the ones that train more, scale wider and run longer end up defining the direction of the field.
Also ,DeepSeek points out that although China’s open-source ecosystem is vibrant, with players like MiniMax, Moonshot and Zhipu continuing to push research and model capabilities, the performance curve of the major proprietary US models from Anthropic, DeepMind and OpenAI has been “accelerating at a much steeper rate in recent months.”
Many had assumed that open-source models would gradually close the gap and eventually catch up with closed-source systems, but in reality the opposite is happening. The performance gap is not converging and is in fact widening. DeepSeek warns China’s open-source community that proprietary systems are showing “substantially stronger advantages on increasingly complex tasks” and that their lead is growing in areas involving high-complexity, multi-step and interactive problem solving.
However, a distinct divergence has emerged in the past months. While the open-source community (MiniMax, 2025; MoonShot, 2025; ZhiPu-AI, 2025) continues to make strides, the performance trajectory of closed-source proprietary models (Anthropic, 2025b; Deep Mind, 2025a; OpenAI, 2025) has accelerated at a significantly steeper rate. Consequently, rather than converging, the performance gap between closed-source and open-source models appears to be widening, with proprietary systems demonstrating increasingly superior capabilities in complex tasks.

DeepSeek identifies three core weaknesses in today’s open-source models:
First, at the architectural level, their heavy reliance on vanilla attention mechanisms severely limits efficiency on long-sequence tasks, creating a bottleneck for scalable deployment and effective post-training.
Second, open-source models lack sufficient compute allocation during the post-training phase, which constrains their performance on hard tasks.
Third, in the domain of AI agents, open-source models lag significantly behind proprietary systems in generalization and instruction following, which limits their effectiveness in real applications.
To address these constraints, DeepSeek first introduced DSA to significantly reduce computational complexity and alleviate the efficiency bottleneck, allowing strong performance even under long-context conditions. It then developed a stable and scalable reinforcement learning protocol that enables substantial compute expansion during post-training. Notably, the post-training compute budget in this framework exceeds ten percent of pre-training cost, which in turn unlocks higher-level capabilities.
Even more importantly, V3.2 integrates “thinking” into tool use for the first time and supports both thinking and non-thinking modes for tool invocation.
DeepSeek explains that it created a large-scale agent training data synthesis pipeline that generates a wide range of “hard-to-solve but easy-to-verify” reinforcement learning tasks, covering more than 1,800 environments and over 85,000 complex instructions.
This significantly improves the model’s generalization ability. As shown in the results below, V3.2 achieves the highest performance among open-source models on agent evaluations. The team notes that it did not tailor its training to the specific tools used in these benchmarks, which is why they believe “V3.2 will exhibit strong generalization in real-world applications.”
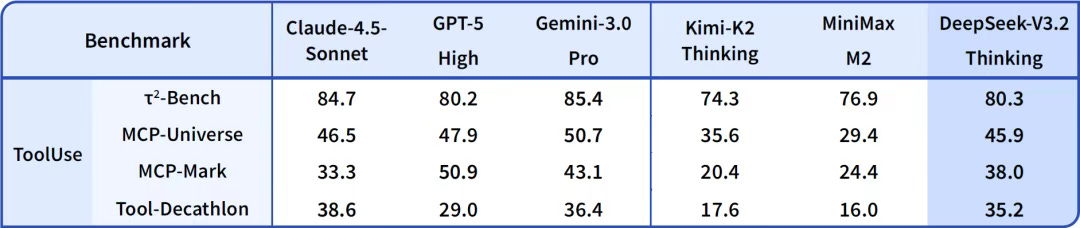
DeepSeek also acknowledges its shortcomings, especially when compared with frontier proprietary models such as Gemini 3.0 Pro.
First, because its total training FLOPs are lower, V3.2 still lags behind leading closed-source models in the breadth of its world knowledge. The team plans to address this gap in future iterations by increasing the scale of pre-training compute.
Second, token efficiency remains a challenge. V3.2 often requires longer generation trajectories, meaning more tokens, to reach the output quality of models like Gemini 3.0 Pro. Future work will focus on increasing the “intelligence density” of its reasoning chains to improve efficiency.
Despite the above, sparse attention is doing heavy lifting here. Even though V3.2 generates more tokens than peer models in benchmarks, its inference cost remains manageable. The team has acknowledged that the next major step is to increase the density of reasoning chains so that shorter outputs can contain more information and complete tasks with higher precision.
Third, its performance on highly complex tasks still falls short of frontier models, and further improvements in the base model and post-training methods are needed.
I think what’s more important is not the model’s already impressive raw performance, but the shockwaves it sent through the industry are even more telling. Many application-focused companies have long tried to rely on a capability gap in foundation models to build moats. The rapid rise of open source models is now weakening that moat. DeepSeek spent a full year pushing the V3 series to its limits, and this process reminded the industry that many of the so called walls people think they hit are not real ceilings but the result of insufficient optimization and insufficient investment.
The roadmap that DeepSeek has demonstrated by continuously scaling models, data, context and reinforcement learning has now become much clearer. For the next several years this is likely to remain the core direction of frontier AI development. There is no shortcut and the only way forward is persistent scaling and long term refinement until competitors can no longer keep pace.
This release also pushed people to look ahead to what comes next. Many members of the technical community are now speculating that since the team has already spent a year squeezing everything possible out of V3, the next significant leap might be arriving soon and that it may well be V4. After all V3.2 is fundamentally still a low cost optimization within the V3 family and the DSA approach is still early stage with enormous room for further evolution.
Hi! This is a fascinating read, and hopefully someday I can learn to read published papers half as well as you can!
Quick question: When you cite DeepSeek’s comments that proprietary (closed-source) models are accelerating their progress beyond open-source, why do you think this may be the case? What is the difference between closed/open source that would give this edge—other than perhaps funding and chips?
Again, loved the article, and the name “geopolitechs“!