
LongCat-2.0: China's Most Unexpected AI Model
In 2026, frontier-scale AI work can emerge from places that American policy and foreign investors were not watching closely enough.

A Chinese food-delivery giant has just made one of the more interesting moves in AI this week.
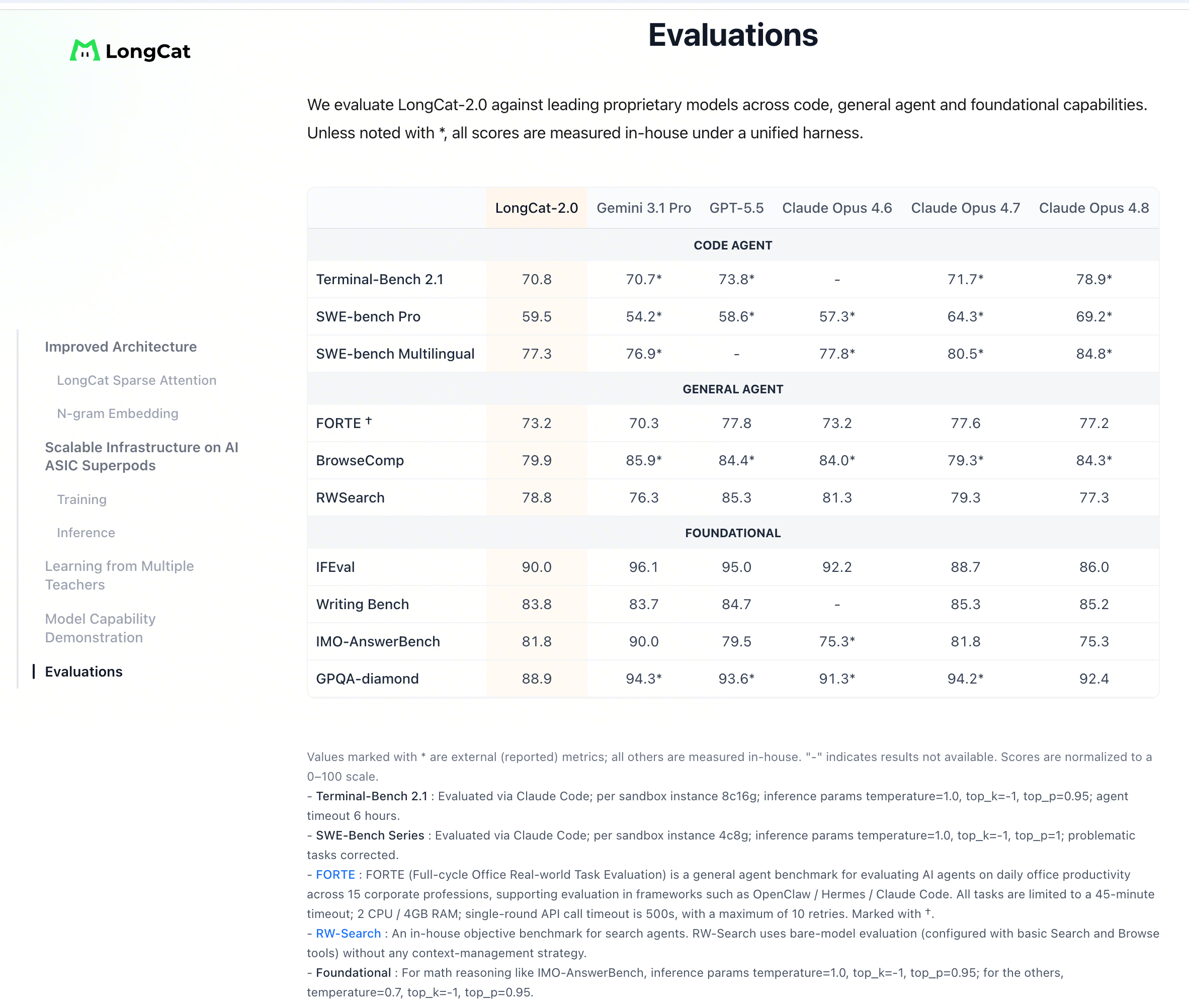
LongCat-2.0, released today by Meituan, is a 1.6 trillion-parameter MoE model with about 48 billion parameters activated per token, trained on more than 30 trillion tokens and built for agentic coding. It supports a 1 million-token context window, and Meituan says the full pretraining run and large-scale deployment were completed on a 50,000-card cluster of domestic Chinese chips, then quietly tested in the open as Owl Alpha on OpenRouter before the company revealed what it was.
That is already enough to make it notable. Most discussion around export controls has focused on whether Chinese labs can continue to train frontier-scale models without access to the latest Nvidia GPUs. Meituan's announcement does not settle that argument, but it does narrow it. A company better known outside China for food delivery and local services is now saying, in plain terms, that it doesn’t need Nvidia GPUs to run a trillion-parameter-class model both in training and in inference.
Meituan's own announcement says LongCat-2.0 was trained from scratch, used more than 30 trillion tokens of pretraining data, and ran on a domestic cluster where the team had to solve communication faults, memory pressure, numerical stability, deterministic operators, and distributed recovery at very large scale. The LongCat blog adds another number: more than 35 trillion tokens consumed during the full training run and deployment validation, again on domestic chips, with no rollback and no unrecoverable loss spike.
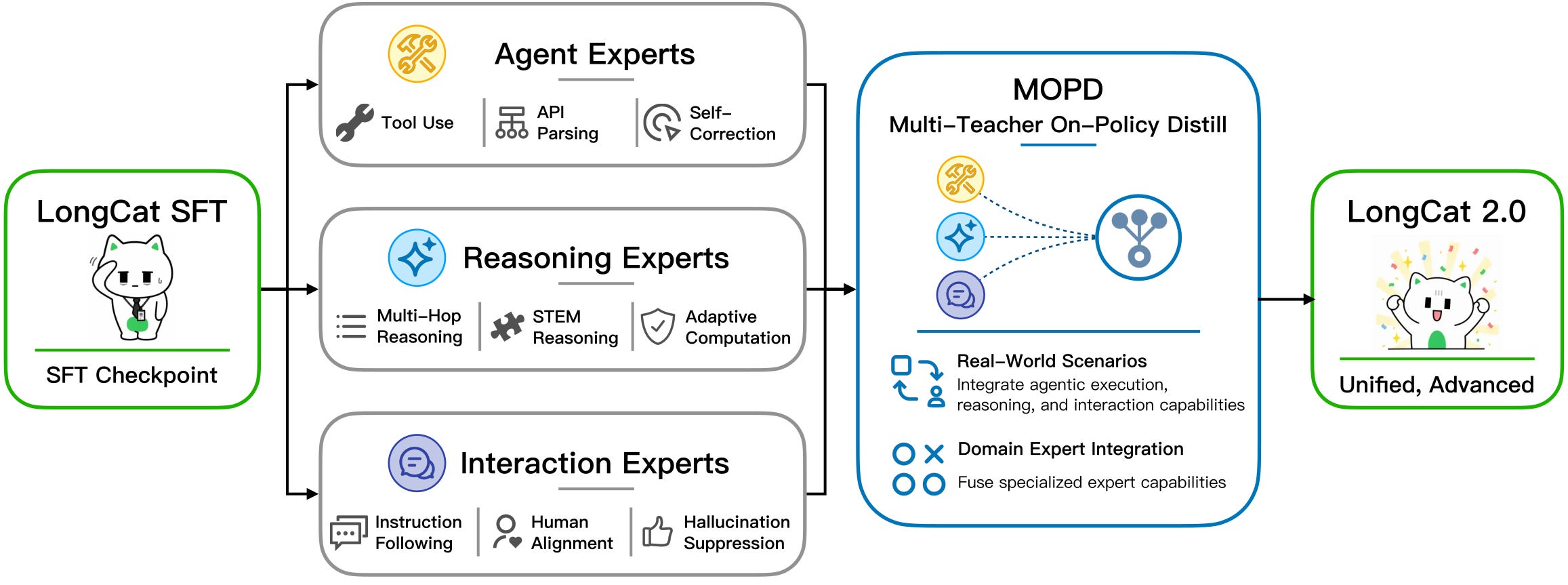
They imply that the harder problem was not merely getting a single large run to start, but keeping a large system stable enough to finish. Meituan also says the architecture was shaped around agentic coding: sparse attention for long context, dynamic token-level compute allocation, and an MoE layout designed for coding, reasoning, and interaction tasks rather than generic chatbot performance.
This is an important distinction. The company is not presenting LongCat-2.0 as a universal answer to every benchmark. It is presenting it as a model meant to work in code understanding, repository-scale modification, tool use, and multi-step execution. That is a narrower claim, but a more commercially legible one.
On June 29, the official Meituan LongCat account on X wrote: "Owl Alpha on OpenRouter — that's us." The post added that Owl Alpha had reached the global top three by daily volume on OpenRouter, while ranking first on Hermes Agent, second on Claude Code, and third on OpenClaw by monthly volume. It also said the stealth phase was ending and Owl Alpha would retire soon.
That single sentence explains why the LongCat launch felt oddly familiar to developers who had been spending time around coding agents. They had already been using the model. They just had not been told what it was.
Rather than introducing a branded model and then waiting for adoption, Meituan appears to have done the reverse. It let the model circulate in a neutral developer environment under a different name, watched whether people actually chose it for real work, and only later attached the company brand. By the time the identity was disclosed, the model already had usage, rankings, and a reputation of its own.
It would be wrong, though, to say that Meituan had been secretly absent from the open-source community until now. The stronger version of the claim is more interesting: the team had been visible for some time, but its flagship coding model was not.
The Hugging Face organization meituan-longcat explicitly identifies itself as Meituan LongCat. Its page shows a continuing release history across models, datasets, benchmarks, spaces, and technical reports. LongCat-2.0 appeared there as a new model update, but it sits alongside earlier projects such as LongCat-Next, LongCat-Flash-Prover, LongCat-Video, LongCat-AudioDiT, WBench, LARYBench, MineExplorer, and LoHoSearch.
The meituan-longcat organization has 35 public repositories on GitHub as well, including LongCat-2.0, LongCat-Flash-Chat, LongCat-Next, LongCat-Video, LongCat-Image, and various supporting components. The organization page also says it has no public members, which is a small but telling detail. The code and assets were public; the people behind them were kept in the background.
The arXiv record shows LongCat-Flash, LongCat-Flash-Thinking, LongCat-Flash-Omni, LongCat-Next, and LongCat-Video technical reports across text, reasoning, multimodal interaction, and generative media. There were public model cards and repositories. There were datasets and benchmarks. There was an API platform with a visible update history, including the release of LongCat-Flash-Chat and later the rollout of LongCat-2.0-Preview.
Seen this way, Owl Alpha was not a detour from the LongCat strategy. It was a natural extension of it. The public repositories built continuity. The anonymous OpenRouter deployment built proof of use. The June 2026 reveal tied the two together.
LongCat-2.0 does not invalidate the logic behind U.S. export controls. Restrictions still raise cost, slow access, complicate scaling, and force Chinese firms into harder engineering trade-offs. But the Meituan case does put pressure on one of the simpler assumptions behind the policy: that denying the newest Nvidia stack would prevent Chinese actors from training and serving frontier-adjacent systems at very large scale.
What Meituan is really showing is that the binding constraint has shifted. The old question was whether domestic Chinese hardware could, in principle, replace imported accelerators at the high end. The newer question is whether domestic hardware, plus enough systems engineering, can support serious models for real users. Those are not the same question. LongCat-2.0 is interesting because it tries to answer the second one.
For all the specificity around cluster size and training scale, one key piece is still missing: Meituan has not publicly named the chip supplier or the chip model.
The official language stops at "domestic chips" and "domestic compute." Mainstream coverage in outlets such as Xinhua, People's Posts and Telecommunications News, Sina Tech, and IT Home repeats that phrasing without identifying a vendor. The LongCat blog is equally careful. It says domestic chips, not Ascend, not Muxi, not Suiyuan, not Biren, not Cambricon.
That silence has produced the usual market guessing. Huawei Ascend is the most common candidate in public discussion, largely because it is the ecosystem most people associate with large-scale domestic training. But that remains a guess. There is no official confirmation of supplier or SKU in the material now available. The most accurate sentence one can write at this point is a narrow one: Meituan has publicly claimed full training and inference on domestic Chinese chips, but it has not publicly disclosed which chips those were.
That may be the real significance of LongCat-2.0. A company most outsiders still file under food delivery has shown that, in 2026, frontier-scale AI work can emerge from places that American policy and foreign investors were not watching closely enough.
Interestingly, over the past few days, Meituan's management has made a series of unusually coordinated public efforts to reassure investors. With the company's share price down more than 30% year-to-date and its market capitalization falling below HK$400 billion, CEO Wang Xing acknowledged at the annual shareholders' meeting that the stock's performance over the past few years had been "unsatisfactory" and said he bore "significant responsibility" for it. He also stressed that he has never sold a single share of Meituan since the company was founded, adding that the only change in his holdings, in 2021, resulted from a donation of shares to a charitable foundation rather than any cash-out.
At the same time, Meituan’s CFO Chen Shaohui argued that Meituan is "significantly undervalued" by the market, saying the company plans to resume share buybacks and will gradually monetize parts of its investment portfolio, returning the proceeds to shareholders.
If Meituan wants LongCat-2.0 to matter beyond one news cycle, three things will need to happen. First, the community will need enough access to the weights, reports, and tooling to test whether the architecture and performance claims travel well outside Meituan's own environment. Second, the OpenRouter episode will need to translate into durable developer adoption under the LongCat name, not just curiosity about the unmasking of Owl Alpha. Third, any future disclosure around the chip stack will need to come from official or at least clearly attributable reporting, because right now the supplier question remains open.