
Does China's DeepSeek-V3 make the computing power advantages of US AI companies less important?

In the past few days, the latest version of the DeepSeek project, V3, has burst onto the scene, leaving many people stunned—not only because of its remarkably low training costs but also due to its impressive performance in multiple benchmark tests. According to an analysis, while many similar models are still grappling with enormous GPU requirements and sky-high budgets, DeepSeek-V3 appears to have gained the upper hand in the “rifles vs tanks” confrontation through a set of ingenious architectural and engineering techniques.
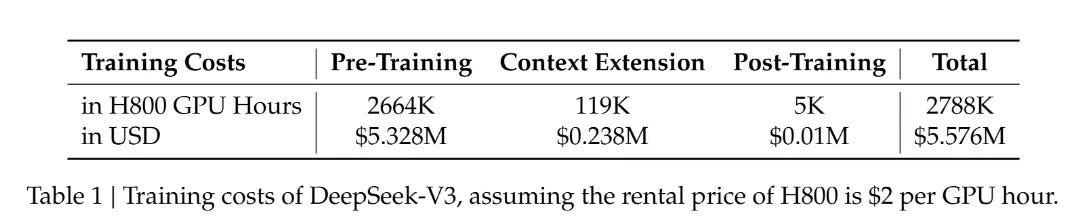
According to the V3 paper, the total training process consumed about 2,788k H800 GPU hours. At a rental rate of 2 US dollars per GPU hour, the total cost comes to only around 5.58 million USD. Compared to the tens-of-billions-of-dollars investments that some big-name large-scale model R&D projects demand, V3 seems to have achieved jaw-dropping results with a relatively modest budget.
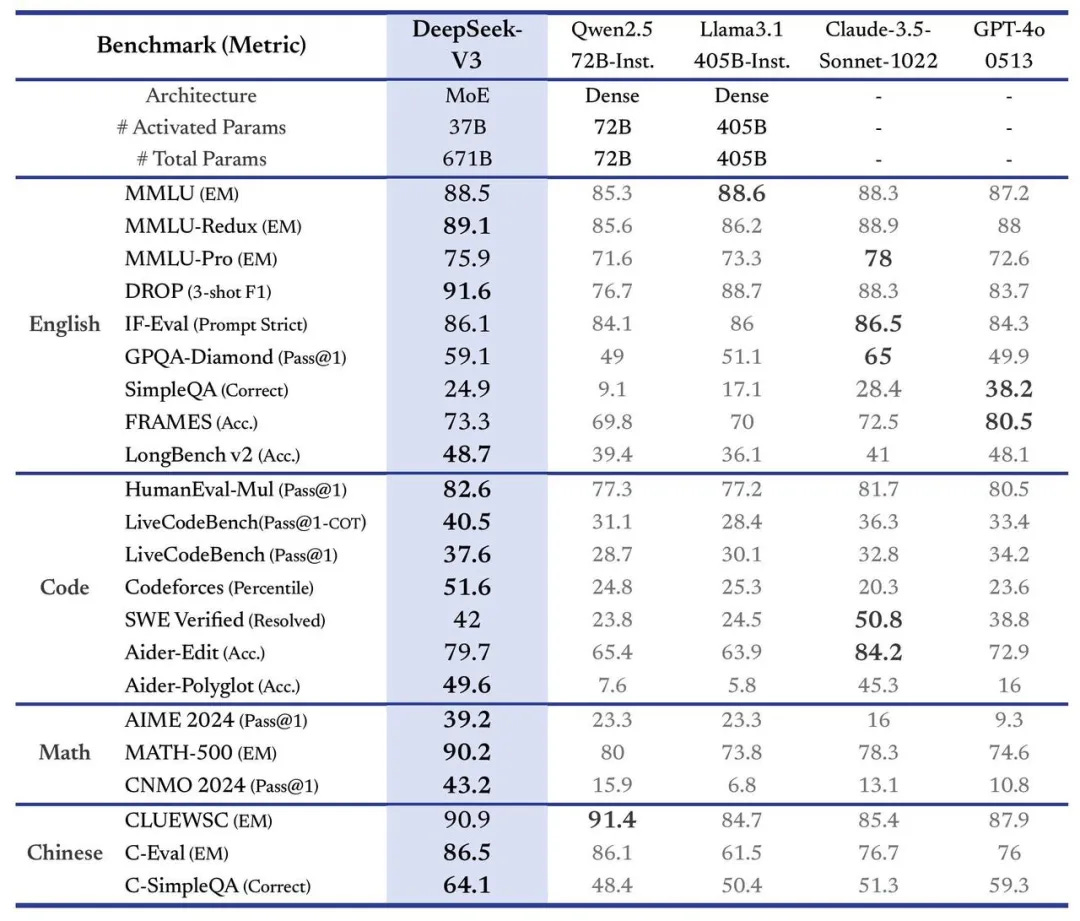
In various comparative tests, V3 has gone head-to-head with leading models like GPT-4o and Claude 3.5; in code generation and mathematical reasoning, it even surpasses certain derivative versions of larger models on multiple metrics. It’s no surprise, then, that prominent AI figure Andrej Karpathy remarked on social media that V3 shows how to accomplish meaningful research and engineering breakthroughs under resource constraints—sparking discussions about whether large models truly need enormous GPU clusters.
Plenty of people have already delved into the technical aspects of the DeepSeek-V3 paper. It introduces a multi-head latent attention (MLA) mechanism, a sparse-activation MoE architecture, and an elegant load-balancing strategy to boost training efficiency. Meanwhile, common practices like large-scale parallelism, communication optimization, and low-precision training have been pushed even further. Rather than restating these technical details, though, I’d like to focus on how its “mixture-of-experts (MoE)” model approach influences computational requirements and the model’s generalization capabilities.
At its core, MoE replaces the feed-forward network in a Transformer with multiple “expert” modules. A gating network then decides which tokens get processed by which experts. The upside is faster training and higher inference speeds, though it places a huge burden on memory—since all experts need to be loaded in parallel. MoE can excel in specialized tasks but often runs into issues like poor generalization and a tendency to overfit. It also demands highly precise fine-tuning; without a clear idea of future inference targets, MoE may fail to deliver.
To a large extent, DeepSeek-V3 is a “reasoning model.” Rather than focusing on broad-spectrum tasks like other large models, it directs its resources toward specific goals—mainly code and math—making it possible to “do more with less” and avoid burning through compute in areas it doesn’t aim to cover.
Another highlight of DeepSeek-V3 is its bold use of FP8 precision during training. This was previously seen as highly risky, but V3 managed to pull it off. It’s akin to a student who has already studied a particular problem multiple times and can now solve it rapidly under exam conditions. Once this approach proves viable, it could dramatically cut training expenses and time.
Part of the reason OpenAI and Anthropic require such massive budgets is that they are at the forefront of exploring entirely “new capabilities,” entailing countless dead ends and failed attempts. In contrast, DeepSeek essentially worked “with the answers already in hand,” heading straight for efficiency and practicality—and thus avoiding much trial and error.
Although V3 demonstrates a high return on a relatively small investment in the inference setting, acquiring broad “general-purpose capabilities” still demands vast training data and sweeping compute resources. Companies chasing comprehensive large-model functionalities will continue fervently competing over compute. The road to higher cognitive levels is inherently long and arduous.
GPT-5 has yet to make any major public progress largely because it aims to extend large-model reach into the physical world. Multimodal data dwarfs text in complexity, and the engineering challenge grows exponentially. Bestowing AI with “embodied intelligence” requires additional sensors and real-world data—elements that guarantee continued high spending and acceleration of the arms race.
The success of DeepSeek-V3 will undoubtedly prompt a surge of applications worldwide. If a highly competitive inference model can be built for under ten million dollars, then medium-sized and smaller teams may see explosive growth next year. “Compute providers”—akin to “shovel vendors” during a gold rush—will also get a boost.
For America’s top tech companies, any breakthrough at the cutting edge of large models still requires hundred- or even thousand-fold levels of investment. Progress at that frontier means exploring uncharted territory. However, DeepSeek-V3’s effective completion of “off-the-shelf methods” with a small budget might lead these companies to focus more on cost-effectiveness for inference applications, possibly borrowing some insights from V3 in product development.
Should both Chinese and American AI applications rush to market next year, the need for compute will only increase further. Only when enough companies genuinely believe they can “strike gold” will they race to buy “GPU shovels.” That’s the cyclical nature of supply and demand: the more success stories they see, the more willing they’ll be to invest heavily.
Which AI applications have the most potential in terms of capital? For specialized professional areas—mathematics, chip design, scientific research—AI systems can significantly boost efficiency. These “high-end” models certainly carry commercial appeal but may not be the best fit for every company. The more broadly lucrative targets are those enabling frequent “connections” among people: AI assistants or agents that can gather users and link to myriad services or other models. Their propensity for viral spread translates into exponential growth. Purely functional small tools, however helpful, lack the connectivity to scale rapidly in a capital sense.
OpenAI aims to experiment with humanoid robots, and Elon Musk is making a full push to build Tesla’s real-world data framework. Both directions confirm that text and images alone fall short when an intelligent system must truly interact with its environment. Future large models will need to perceive and manage higher-dimensional information to perform real “experiments and actions,” and that inevitably calls for another high-stakes round of development. Anyone trying to build AI for the real physical world will face yet another wave of resource-intensive competition; there’s no pause button.
The emergence of DeepSeek-V3 shows that, in the race for large-model advancement, certain highly targeted technical and training strategies can slash costs while delivering remarkable results in reasoning tasks. It’s a shot in the arm for China’s AI sector and demonstrates to the world that there’s another viable way to develop large models. Though comprehensive “general-purpose” models remain a focal point for major companies, V3’s “small investment, high payoff” strategy may well speed up innovation in specialized fields.
Looking ahead to the coming year, Chinese and American developments in large models and AI applications will likely surge in parallel. Compute suppliers will prosper, while downstream startups and innovations multiply. Those products that capitalize on social and connectivity value—especially those harnessing high-dimensional data—stand the best chance to rise with the help of capital investment. All signs point to the same fate: either double down and grow, or get left behind by faster-moving competitors.